Ruby is a better Perl and in my opinion is an essential language for system administrators. If you are still writing scripts in Bash, I hope this inspires you to start integrating Ruby in to your shell scripts. I will show you how you can ease in to it and make the transition very smoothly.
I’ve learnt a few things from the article:
Debug output, and anything that does not belong in the output of the application should go to STDERR and only data that should be piped to anothe application or stored should go to STDOUT
There’s ARGF in addition to ARGV.
I can ask the user for a password without the password being echoed back to the terminal:
#!/usr/bin/rubyrequire'io/console'# The prompt is optionalpassword=IO::console.getpass"Enter Password: "puts"Your password was #{password.length} characters long."
I can check for return codes and errors via the $? object.
I can trap interrupt signals with Signal.trap().
#!/usr/bin/rubySignal.trap("SIGINT"){puts'Caught a CTRL-C / SIGINT. Shutting down cleanly.'exit(true)}puts'Running forever until CTRL-C / SIGINT signal is recieved.'whiletruedoend
Many sites enable users to follow and be followed by other users. It’s a common feature. Dev.to implements it. Twitter implements it.
Michael Hartl demonstrates an implementation in Chapter 14 of The Ruby on Rails Tutorial. I didn’t really understand what was going on at first. It wasn’t until I’d gained a better understanding of ActiveRecord that I fully comprehended what was going on.
Here, I will explain my understanding of how it works.
Most of my following example is identical to Michael Hartl’s implementation.
What am I trying to implement?
Any user can follow any other user. At the same time, any user can be followed by any other user. The relationship is not reciprocal. That is, if one user follows another user, it is not necessary that the other follows back.
Essentially though, whether or not a user follows or is followed, I am describing two sides of the same relationship – one user points to the other.
I will call a user that follows another user a follower.
I will call a user that is followed by another user a followee.
A user can have many followers. Likewise, a user can follow many followees.
I will describe the relationship between a follower and followee as a followship.
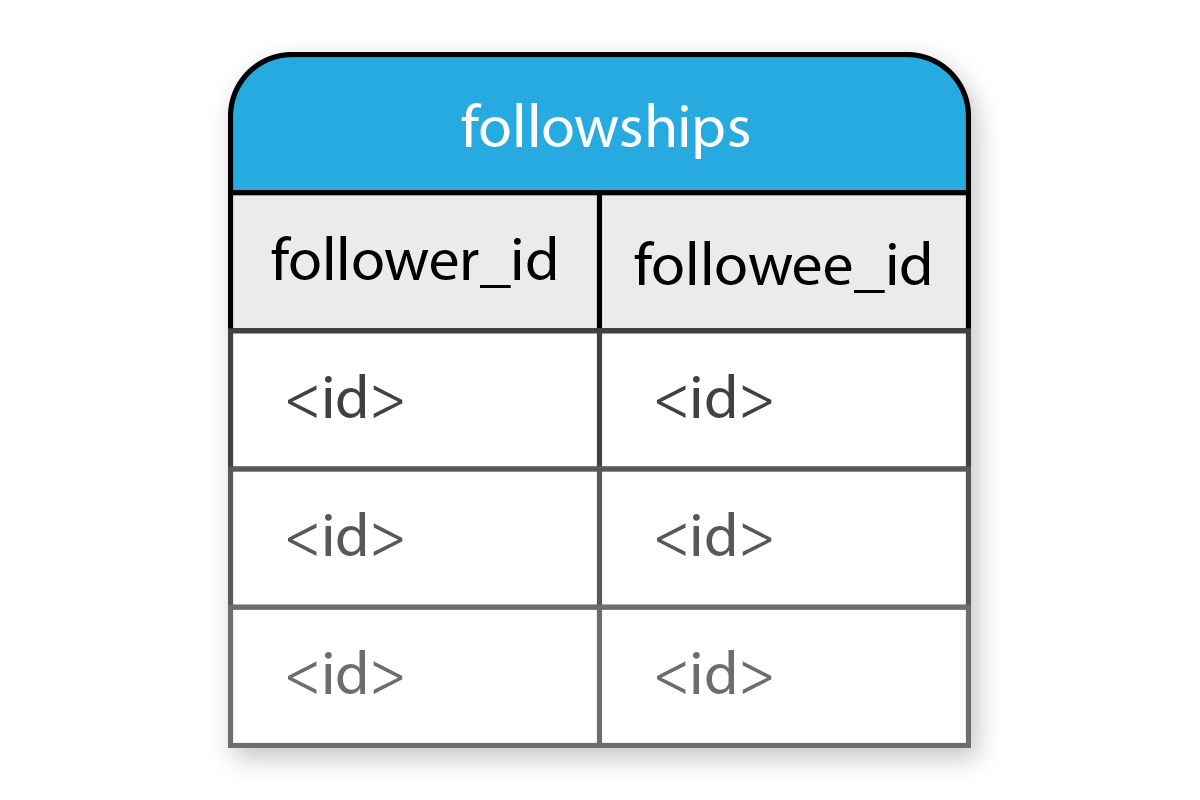
Followships
I now have three concepts: followers, followees and followships.
Followships sounds like the name of a table to me. This table will have two columns. One will point to a follower. The other will point to a followee. Each is referenced by its id.
Knowing this, I can generate a model named Followship. I will add an id column for followers and followees.
(Followships is a special kind of table called a join table. A join table is used to establish many to many relationships – where models can have many of each other.)
I’ll add an index for both follower_id and followee_id since I will want to look up followships by both followers and followees. Also, I’ll place a unique constraint on the rows because it doesn’t make sense that a user follows another more than once.
Before establishing the relationship in the model, there’s a couple of things to be aware of.
Firstly, an association name does not have to share the name of the model it points to. Let’s say I have the classes User and Project. A user can have many projects:
classUser<ApplicationRecordhas_many:projectsend
Each Project belongs to a single User. I could establish the relationship like this:
classProject<ApplicationRecordbelongs_to:userend
But I would like to refer to the user as the owner of the project.
So how about this?
classProject<ApplicationRecord# This will not work!belongs_to:ownerend
Using the above, Rails believes that I want to reference a model name Owner. It infers the class name of the associated object from the name I’ve provided.
Now that I know this technique, I can create belongs_to associations for a followship’s follower and followee. Despite their names, both columns point to User.
Note: because both of these are belongs_to associations, it is the responsibility of Followship to record the foreign ids of the rows to which it belongs.
The belongs_to association creates a one-to-one match with another model. In database terms, this association says that this class contains the foreign key. If the other class contains the foreign key, then you should use has_one instead.
One final step here. I want to ensure that both the follower_id and followee_id is present. There cannot be a relationship if one is without the other.
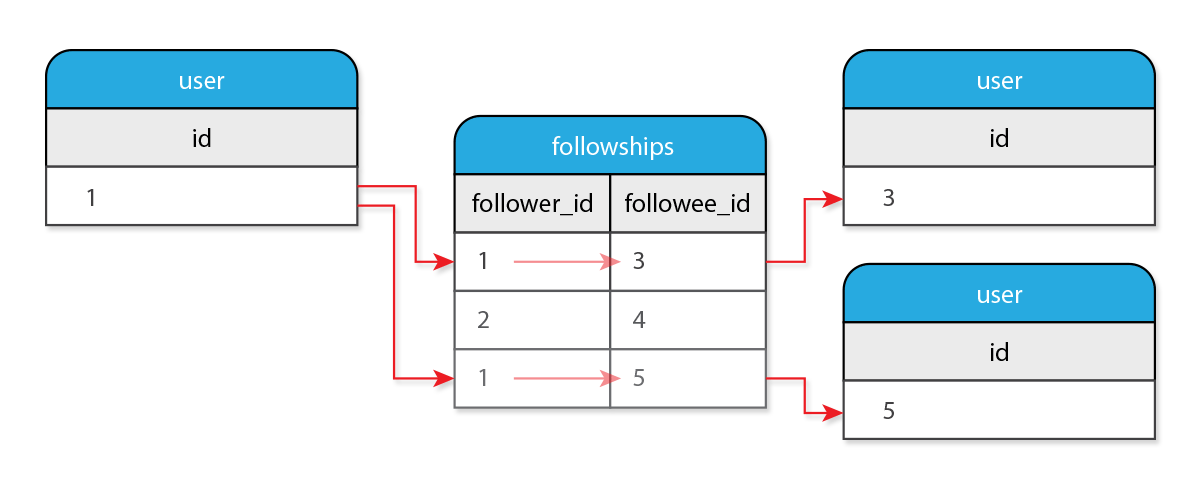
Each row in followships points to a follower_id and a followee_id.
I’ve indexed by both columns and ensured each pairing is unique.
I’ve made sure both ids are present in every row.
I’ve established that Followship belongs to a follower and followee. (In doing so, I’ve had to tell Rails that in both cases I’m actually pointing to User.)
Connecting User to the Followship
From the point of view of User, followships come in two flavours.
Depending on which way you look at it, a followship can either be a relationship in which the user is a follower of another or it can be a relationship in which the user is a followee of the other.
In the first case, I want to establish that the user has many relationships in which it follows another user. I want to tell Rails that it should reference the user by follower_id in the followships table.
I want the User model to declare to Rails:
“I can have many followships where I am following another user.
“I will refer to these followships as follower_followships.
“In this case, I will refer to myself as a follower.
“Store my id in followship’s’ follower_id field.”
# app/models/user.rb# ...# A follower is a user than follows another user.has_many:follower_followships,class_name: "Followship",foreign_key: "follower_id",dependent: :destroy
(Like the project/owner example above, I have given the association a name that is different from the class it points to. I also know that because the other class is on the belonging side of the relationship, it is the other class that stores the id. In this case, the user id is stored as the foreign key follower_id.
Notice that I have also made the relationship dependent on the user existing. If the user is destroyed, so too are any rows in followships that correspond to it.)
All good but I haven’t yet pointed to another user. So far, User points only to the join table.
Through
Join tables are called such because they join one table to another. They are the glue in a has_many/has_many relationship. (They provide the belongs_to association that stores the foreign keys). Relationships are made through the join table.
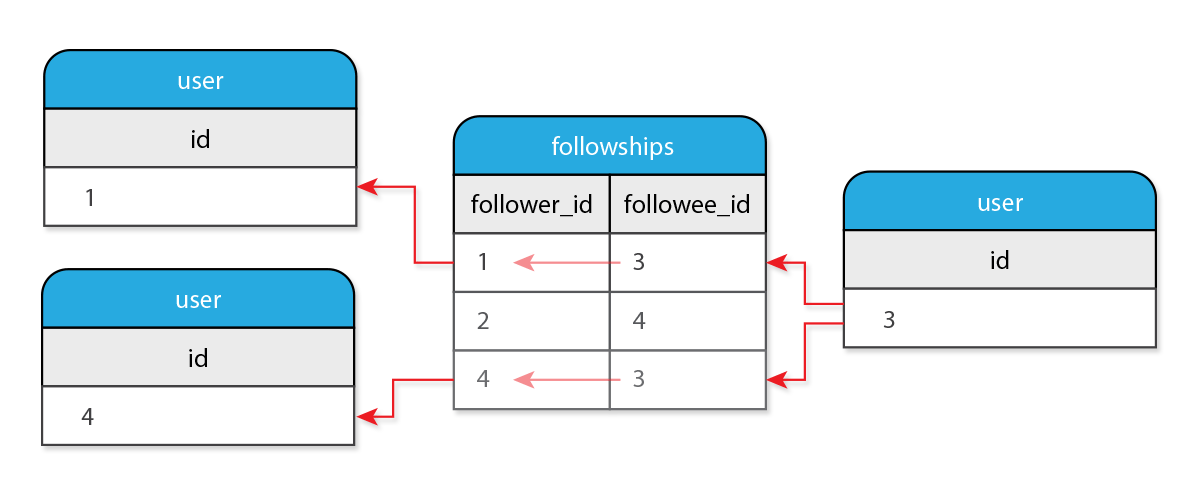
I know that each row has a follower and followee column. I know that if my user follows another, its id will be stored in the follower_id column. I also know that in each row my user is recorded as a follower, there will be the corresponding followee_id.
Now I want the User model to declare:
“I can have many followees.
“I can follow many users. Look up my follower_followships. If you see any, the corresponding followee_id in those rows is the id of the followee I am following.”
Like so:
I declare the has_many association with followeesthrough the previously established follower_followships association:
# app/models/user.rb# To see the users that the user follows, we reference them through the join# table.has_many:followees,through: :follower_followships
So far, the User looks like this:
classUser<ApplicationRecord# A follower is a user than follows another user.has_many:follower_followships,class_name: "Followship",foreign_key: "follower_id",dependent: :destroy# We reference the users that the user follows through the join# table.has_many:followees,through: :follower_followships
Now, I need to do the reverse. I need to establish the other flavour of followship where the user is the followee. A user can be a follower but when other users point to it, it is also a followee.
# A followee is a user that is followed by another user.has_many:followee_followships,class_name: "Followship",foreign_key: "followee_id",dependent: :destroy
And I can look up followers through the join table:
# To see the users that follow a user, we reference them through the join# table.has_many:followers,through: :followee_followships
And now, followees can look up followers through the join table.
A couple of convenience methods
I can now access the users which a user follows by calling self.followees.
Knowing that, I can create two methods that allow me to follow and unfollow users conveniently.
classUser<ApplicationRecord# A follower is a user than follows another user.has_many:follower_followships,class_name: "Followship",foreign_key: "follower_id",dependent: :destroy# To see the users that the user follows, we reference them through the join# table.has_many:followees,through: :follower_followships# A followee is a user that is followed by another user.has_many:followee_followships,class_name: "Followship",foreign_key: "followee_id",dependent: :destroy# To see the users that follow a user, we reference them through the join# table.has_many:followers,through: :followee_followshipsdeffollow(user)followees<<userenddefunfollow(followed_user)followees.deletefollowed_userendend
In the wild
Dev.to’s implementation is more complicated as it deals with polymorphic associations. However, something similar can be seen in mentor_relationship.rb and in the relevant part of User.rb:
I’ve established the Followship model belongs to a follower and followee.
The corresponding table followships is a join table. Users will relate to each other as followers and followees through this table.
Each row in the followships table stores a follower_id and a followee_id.
I’ve established the a User can have many follower_followships and many followee_followships.
A follower_followship (a followship in which the user does the following) is where the user id is stored under followship’s follower_id column.
A followee_followhsip (a followship in which the user does is followed) is where the user’s id is stored as a foreign key under followship’s followee_id column.
A user can have many followees through follower_followships.
A user can have many followers through followee_followships.
I’ve added a couple of convenience methods to follow and unfollow users.
What did I need to understand to get here?
A model that belongs to another model is responsible for storing the other model’s id as a foreign key.
I can establish many to many relationships through a join table.
I can give a relation a name that is different from the name of the class it refers to.
I don’t think that’s intuitive enough though. Since I’m asking for the parent step, it should be more like:
b.parent# => #<Step:0x00007fdf24b916e8
Setting up the custom name is simple. I can supply the name of my choosing. Then, all I need to do is specify the class name and foreign id in the options.
It took me an hour or so of frustration to figure out why a method was being called multiple times despite my attempt at memoizing its return value.
The problem
My problem looked a bit like this.
defhappy?@happy||=post_complete?end
My intention was that value of post_complete? would be stored as @happy so that post_complete? would be fired only once.
However, that’s not guaranteed to happen here. post_complete? might be evaluated and its value assigned to @happyevery time I call happy?.
Can you see why?
@happy||=post_complete?
What’s going on?
The question mark denotes that post_complete? is expected to return a boolean value. But, what if that value is always false?
Another way of writing the statement is:
@happy||@happy=post_complete?
In the above example, I want to know if at least one of the sides is true.
Remember that if the left-hand side of an || statement is false, then the right-hand side is evaluated. If the left side is truthy, there’s no need to evaluate the right side – the statement has already been proven to be true – and so the statement short circuits.
If I replace post_complete? with boolean values, it’s easier to see what is happening.
In this example, @happy becomes true:
defhappy?@happy||@happy=true# @happy == trueend
However, in this example, @happy becomes false:
defhappy?@happy||@happy=false# @happy == falseend
In the former, @happy is falsey the first time the method is called, then true on subsequent calls. In that example, the right-hand side is evaluated once only. In the latter, @happy is always false and so both sides are always evaluated.
When using the ||= style of memoization, only truthy values will be memoized.
So the problem is that if post_complete? returns false the first time happy? is called, it will be evaluated until it returns true.
A solution
So how do I go about memoizing a false value?
Instead of testing the truthiness of @happy, I could check whether or not it has a value assigned to it. If it has, I can return @happy. It if hasn’t, then I will assign one. I will use Object#defined?.
defined? expression tests whether or not expression refers to anything recognizable (literal object, local variable that has been initialized, method name visible from the current scope, etc.). The return value is nil if the expression cannot be resolved. Otherwise, the return value provides information about the expression.
Referring back to the documentation, there’s one thing I need to be aware of. This isn’t the same as checking for nil or false. It’s a bit counterintuitive, but defined? doesn’t return a boolean. Instead, it returns information about the argument object in the form of a string:
So, as long as the variable has been assigned with something (even nil), then defined? will be truthy. Only if the variable is uninitialized, it returns nil.
Of course, you can guess what happens when we set the variable’s value to false.
Prompted by Valentin Baca’s comment, I’ve reassessed my original solution. Do I really need to check whether or not the variable is initialised or is checking for nil enough?
@happy.nil? should suffice as I’m only interested in knowing that the variable is nil rather than false. (false and nil are the only falsey values in Ruby.)
I now know that the ||= style of memoization utilizes short-circuiting. If the left-hand side variable is false, then the right-hand part of the statement will be evaluated. If that’s an expensive method call which always returns false, then the performance of my program would be impacted. So instead of ||= I can check if the variable is initialized or I can check if it’s nil.
A small simple object, like money or a date range, whose equality isn’t based on identity.
Martin Fowler
Objects in Ruby are usually considered to be entity objects. Two objects may have matching attribute values but we do not consider them equal because they are distinct objects.
In this example a and c are not equal:
classPanserbjorndefinitialize(name)@name=nameendenda=Panserbjorn.new('Iorek')b=Panserbjorn.new('Iofur')c=Panserbjorn.new('Iorek')a==c#=> => false# Three distinct objects:a.object_id#=> 70165973839880b.object_id#=> 70165971554200c.object_id#=> 70165971965460
Value objects on the other hand, are compared by value. Two different value objects are considered equal when their attribute values match.
Symbol, String, Integer and Range are examples of value objects in Ruby.
Here, a and c are considered equal despite being distinct objects:
a='Iorek'b='Iofur'c='Iorek'a==b#=> falsea==c#=> true# Three distinct objects:a.object_id#=> 70300461022500b.object_id#=> 70300453210700c.object_id#=> 70300461053840
How can I create a value object?
Say I want a class to represent the days of the week and I also want instances of that class to be considered equal if they represent the same day. A Sunday object should equal another Sunday object. A Monday object should equal another Monday object, etc…
Now, I am going to instantiate three objects to represent the days of the week on which I eat pizza, pay the milk man, and put out the recycling for collection:
I know that I eat pizza for dinner the same day that I put out the recycling. I consider these objects to represent the same thing: Thursday. They should be equivalent. But they’re not:
pizza_day==recycling_collection_day#=> false
That’s because they’re not yet value objects. #== compares the identities of the objects.
I should override #==. I will use pry to find out where the method comes from so we can see how it derives its current behaviour.
== returns true only if obj and other are the same object. Typically, this method is overridden in descendant classes to provide class-specific meaning.
Aha! The class specific meaning in this case is I want to compare its instances by value.
I know that these objects expose an integer. It makes sense to compare against that but I don’t want to compare a day with an actual integer. Thursday should not be equivalent to the number 5.
I also know that a DayOfWeek exposes a string as well. It follows that any equivalent days would return matching string and integer values:
I have aliased #eql? to #==. The BasicObjectdocumentation explains:
For objects of class Object, eql? is synonymous with ==. Subclasses normally continue this tradition by aliasing eql? to their overridden ==
Bingo! We have value objects. pizza_day and recycling_collection_day are considered equivalent:
pizza_day==recycling_collection_day#=> true
I could override other comparison methods, #<==>. <=, <, ==, >=, > and between? as it makes sense to say that Monday is less than Tuesday or Friday is greater than Thursday but I have decided that’s not needed for now.
There is however, one more important step that I need to implement. These objects are equivalent, so when used as a hash key I would expect them to point to the same bucket.
Two objects refer to the same hash key when their hash value is identical and the two objects are eql? to each other.
A user-defined class may be used as a hash key if the hash and eql? methods are overridden to provide meaningful behavior. By default, separate instances refer to separate hash keys.
Following that advice, I need to change the default behaviour of #hash. I already know that integers in Ruby are value objects. I can see that equivalent integers always return the same #hash.
a='Svalbard'b='Svalbard'# Note the different object ids:a.object_id#=> 70253833847520b.object_id#=> 70253847146940'Svalbard'.object_id#=> 70253847210020# The hash values of equivalent strings match:'Svalbard'.hash=='Bolvanger'.hash#=> false[a,b,"Svalbard"].map(&:hash).uniq.count#=> 1'Svalbard'.hash==('Sval'+'bard').hash#=> true
I will generate the hash using its string and integer properties.
We now know the difference between an entity object and a value object. We have learned that we need to override both #hash and #== if our value objects are to be used as hash keys. And, we have learned that structs provide value object behaviour straight out of the box.
The Kernel module is included by class Object, so its methods are available in every Ruby object.
It’s basically a bunch of helper methods made available to every class.
Kernel#hash seems to be undocumented though. It’s not in in the docs for the Kernelmodule. Though, that page does point towards the Object class page for information on Kernel instance methods. But there’s nothing on it there either.
The explanation to why #hash needs to be overridden when #eql is changed is in the Hash docs.
Two objects refer to the same hash key when their hash value is identical and the two objects are eql? to each other.
Two objects can have the same hash value but be unequal however this would be detriment to the speed of the hash.
So when keying by multiple objects, so long as their hash and eql? values match, they will point to the same bucket.
Andrew Berls writes about the naked asterisk in this post. I too stumbled across it whilst looking through Rails source.
Andrew says:
So what’s the deal with the unnamed asterisk? Well, this is still the same splat operator at work, the difference being that it does not name the argument array. This may not seem useful, but it actually comes into play when you’re not referring to the arguments inside the function, and instead calling super. To experiment, I put together this quick snippet:
classBardefsave(*args)puts"Args passed to superclass Bar#save: #{args.inspect}"endendclassFoo<Bardefsave(*)puts"Entered Foo#save"superendendFoo.new.save("one","two")
The globbed arguments are automatically passed up to the superclass method. Some might be of the opinion that it’s better to be explicit and define methods with def method(*args), but in any case it’s a neat trick worth knowing!